Alternating direction method of multipliers (ADMM)¶
The decomposition methods implemented in this branch are based on the consensus variant of the alternating direction method of multipliers (ADMM).
Theoretical background of consensus ADMM¶
ADMM belongs to a family of decomposition methods based on dual decomposition. To understand its working principle, let’s have a look at the following problem:
where indices \(1, 2\) denote the first and second subsystems (e.g. two regions in an energy system model), with \(\boldsymbol x_1, x_2\) as the sets of variables which are internal to the subsystems 1 and 2 respectively (e.g. set of generated power by processes in these subregions), \(\boldsymbol y\) as the coupling variables between the subsystems 1 and 2 (e.g. the power flow between these subregions).
By creating two local copies of the complicating variable (\(\boldsymbol y_1, \boldsymbol y_2\)) and introducing a “consensus” constraint which equates these to a global \(\boldsymbol y_g\), this problem can be reformulated as follows:
where \(\boldsymbol \lambda_1, \boldsymbol \lambda_2,\) are the dual variables (Lagrange multipliers) of the two consensus constraints respectively. The augmented Lagrangian of such a problem looks as follows (with a set penalty parameter \(\rho\)):
From here, the essence of the consensus ADMM lies on decoupling this Lagrangian by fixing the global value and the Lagrangian multipliers which correspond to the consensus variables. For this, an arbitrary initialization can be made (\(\boldsymbol y_g^0:=\boldsymbol y^0\), \(\boldsymbol \lambda_{1,2}^0:=\boldsymbol \lambda^0\)).
Then the following steps are applied for each iteration \(\nu=\{1,\dots, \nu_\text{max}\}\):
- Through the fixing (or initialization, in case of the first step) of the global value and the Lagrangian multipliers, the decoupled models can be solved independently from each other:
- Using these solutions, an averaging step is made to calculate the global value of the coupling variable to be used in the next iteration:
- Then, the consensus Lagrangian multipliers need to be updated for each subproblem:
- Using the values obtained from 2) and 3), the primal and dual residuals are calculated for each subproblem:
The steps 1, 2, and 3 and 4 are followed until convergence, which corresponds to the condition of primal and dual residuals being smaller than a user-set tolerance. For a more detailed description of consensus ADMM, please refer to the following material: https://stanford.edu/class/ee367/reading/admm_distr_stats.pdf.
Theoretical background of the asynchronous consensus ADMM¶
The consensus ADMM, whose steps were described above, is a synchronous algorithm. This means, each subproblem needs to be solved (step 1), in order for the updates (steps 2, 3) to take place before moving onto the next iteration. When the subproblems are solved in parallel for runtime benefits, this may lead to a so-called “straggler effect”, where the performance of the algorithm is constrained by its slowest subproblem. This is often the case when the subproblems differ in sizes considerables (leading the small subproblems to have to wait for a larger problem to be solved).
In order to tackle this issue, an asynchronous variant of ADMM is formulated, where:
- partial information from neighbours (a certain percentage \(\eta\) of the neighbors) is sufficient for each subproblem to move onto the next iteration, and
- the updating steps (2, 3) and the convergence checks take place locally rather than globally.
The specific algorithm is partially based on https://arxiv.org/abs/1710.08938. Here, a brief explanation of the algorithm will be made. For a more detailed description, please refer to this material.
Let us assume that our problem consists of the subsystems \(k\in \{1,\dots,\mathcal N\}\), with each subsystem \(k\) sharing some variable(s) with its neighbors \(\mathcal N_k\). Asynchronicity takes places by each subproblem receiving the solutions from only up to \(\left \lceil{\eta \lVert \mathcal N_k \rVert}\right \rceil\) neighbors before moving on to the next iteration. Since it takes different time for each of these subproblems to receive these information, each subproblem has their own iteration counters \(\nu_k\). A generalized notation of the problem variables are as follows:
| Variable | Description |
|---|---|
| \(\boldsymbol x_k\) | Internal variables of subsystem \(k\) |
| \(\boldsymbol y_{kl}\) | Set of the coupling variables between subsystems \(k\) and \(l\) in subproblem \(k\) |
| \(\boldsymbol y_{k}\) | Set of the coupling variables between subsystems \(k\) and all its neighbors \(\mathcal N_k\) in subproblem \(k\) |
| \(\boldsymbol y_{g,kl}\) | Set of the (now locally defined) global value of \(\boldsymbol y_{kl}\) in subproblem \(k\) |
| \(\boldsymbol y_{g,k}\) | Set of the (now locally defined) global value of all coupling variables \(\boldsymbol y_{k}\) in subproblem \(k\) |
| \(\boldsymbol \lambda_{kl}\) | Set of the Lagrange multipliers for the consensus constraint \(\boldsymbol y_{kl} =\boldsymbol y_{g,kl}\) in the subproblem \(k\) |
| \(\boldsymbol \lambda_{k}\) | Set of the Lagrange multipliers for all consensus constraints \(\boldsymbol y_{k} =\boldsymbol y_{g,k}\) in the subproblem \(k\) |
| \(\rho_{k}\) | Quadratic penalty parameter of the subproblem \(k\) |
The asynchronous ADMM algorithm for each subsystem \(k\) operates as follows:
- Through the fixing (or initialization, in case of the first step) of the global values and the Lagrangian multipliers, the decoupled model can be solved independently in parallel to the others:
- Check if at least \(\left \lceil{\eta \lVert \mathcal N_k \rVert}\right \rceil\) neighbors have new information to provide. If not, wait for it. If a problem \(l\) had already been solved multiple times since the last time information was received from it, pick the most recent information (corresponding to its current local iteration \(\nu_l\)). (
recv()is where this step is implemented): - For each neighbor \(l\) that provided new information, apply a modified averaging step (
update_z()is where this step is implemented).
This update step looks differently than that of synchronous ADMM, as it factors for the inaccuricies which arise from asynchronicity.
- Update (all) consensus Lagrangian multipliers of subproblem \(k\) as usual:
- Update (all) consensus Lagrangian multipliers of subproblem \(k\) as usual:
- To check the convergence of a subproblem, collect all primal and dual residuals from the neighbors. If the maximum of these residuals is smaller than the convergence tolerance set for this subproblem, the subproblem converges:
Interpretation of regional decomposition in urbs¶
In this implementation, the urbs model is regionally decomposed into “region clusters”, where each model site can be clustered flexibly in separate subproblems. Drawing on the generic problem definition mentioned above, a specification of this notation can be made for urbs in the following way:
| Variable | Description |
|---|---|
| \(\boldsymbol x_k\) | Process/storage capacities, throughputs, commodity flows:. within the region cluster \(k\) |
| \(\boldsymbol y_{kl}\) | Power flows/capacities of transmissions between the region clusters \(k\) and \(l\) (e_tra_in(k,l), cap_tra(k,l)) |
Formulation the global CO2 limit in the consensus form The intuition is that, when two region clusters are optimized separately, the coupling between them manifests itself in the transmission power flows and capacities between these clusters. Thereby, they constitute the complicating variables of the problem and hence the linear and quadratic consensus terms will have to be added to the respective cost functions. However, a simplification is made here, by ignoring the transmission capacities in the consensus variables. This simplifies the algorithm without having an influence on the feasibility of the solution, since when the consensus for the power flows for a transmission line is achieved, the capacity of this transmission line will be set for each subproblem as the largest flow passing through this line to minimize the costs. In other words, the consensus of the power flows ensures the consensus of the line capacities.
Formulation the global CO2 limit in the consensus form¶
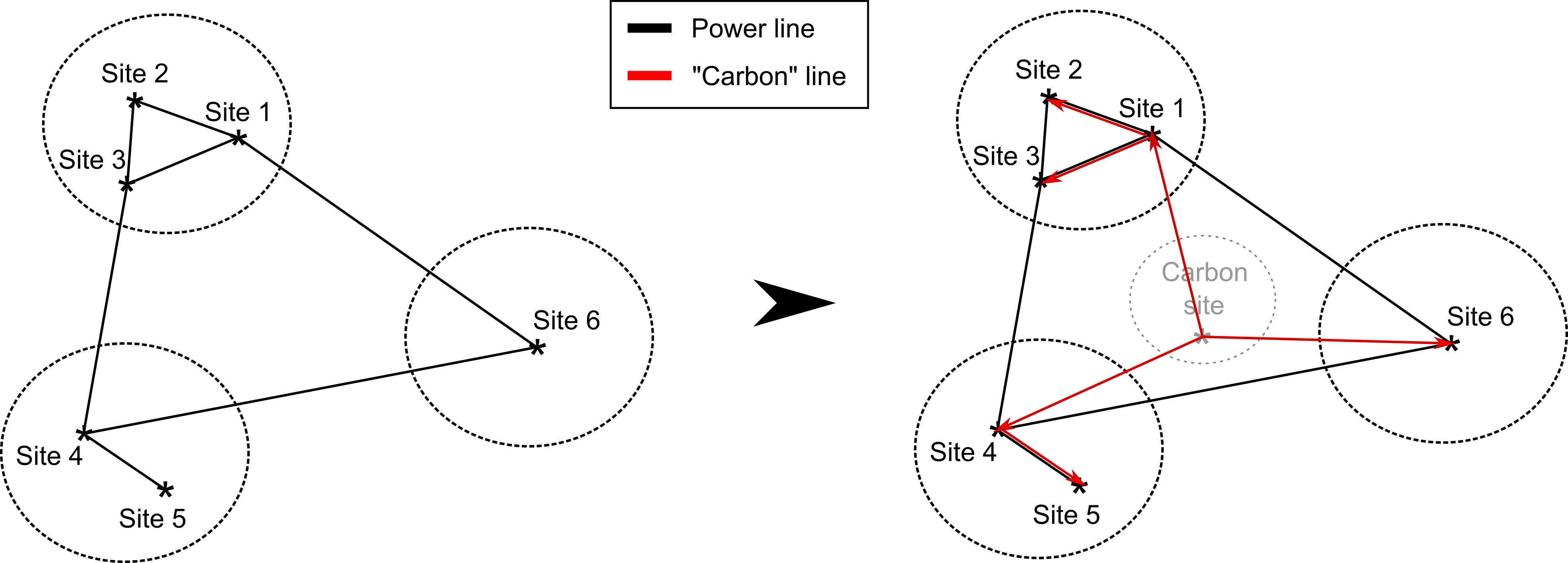
However, the line flows are not the sole coupling aspect in the urbs model. The global CO2 constraint, which restricts the total CO2 emissions produced by all of the regions, also couple the operation of the subproblem with each other. While this is a coupling constraint (and not a coupling variable), a reformulation into a similar consensus form can be made in the following way:
- A “dummy” region cluster (consisting of a single region) called
Carbon siteis created,- A new stock commodity
Carbonis created, which can be created inCarbon sitefor free, with amaxamount equal to the global CO2 limit,- The
Carboncommodity act as “carbon certificates”, such that to each process that emitCO2, it is added as an additional input commodity with an input ratio same as the output ratio ofCO2,- The
Carboncommodity created in theCarbon sitecan be transported to each other sites for free. Therefore, new transmission “lines” are defined for this commodity, with unlimited capacity and no costs.
Now, the commodity flows of Carbon can be treated as an intercluster coupling variable (just like the power flows) and, as long as the consensus is achieved, the global CO2 limit will be respected.