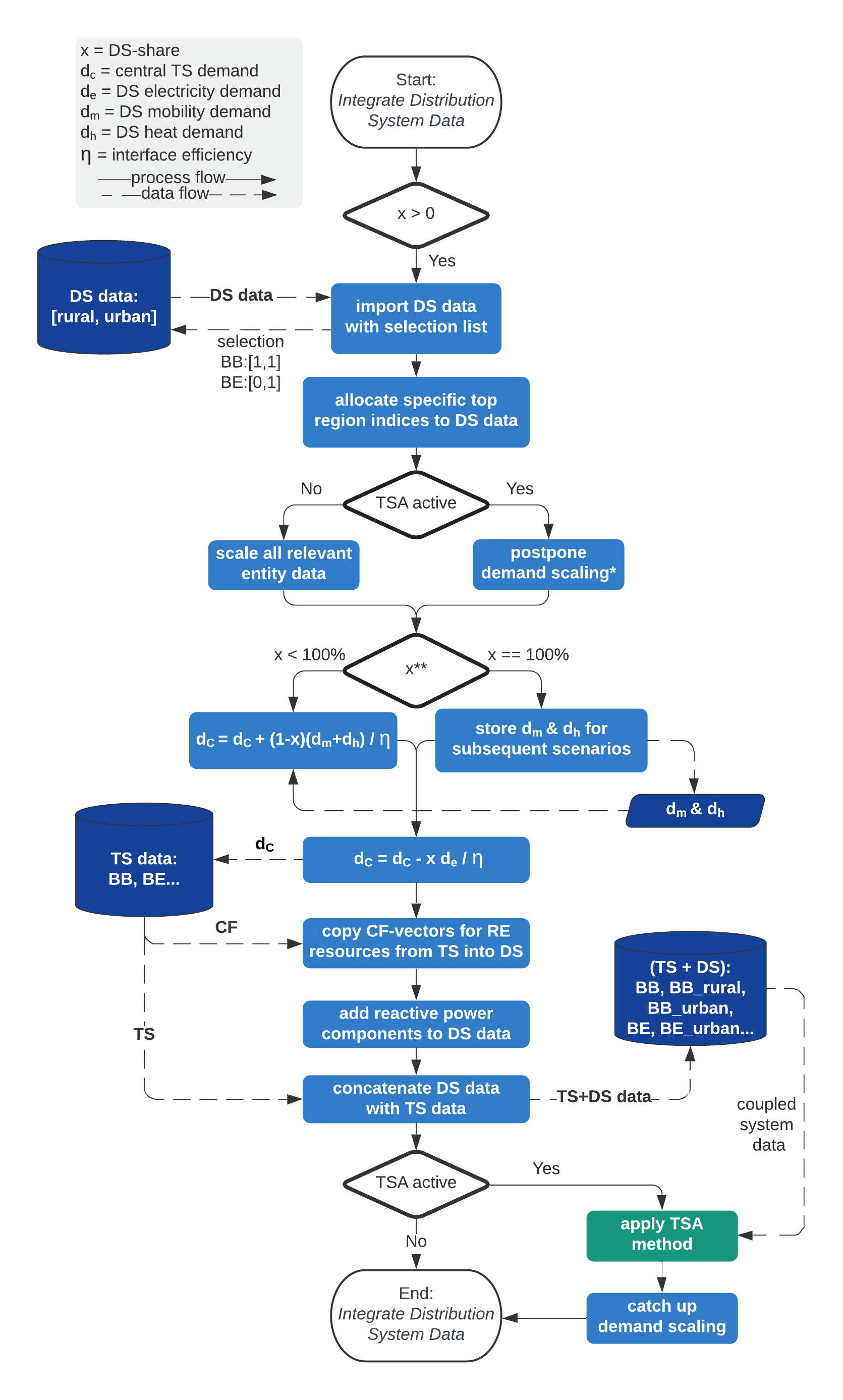
Automated Coupling¶
A central goal in this work is to consider different system levels within a single multi-commodity energy system model for expansion and operation planning.
A key aspect to realize this for our energy system planning approach is to integrate the bottom level microgrids within each associated top level region.
In the following, a walkthrough on the transdisthelper.py script will be given to establish understanding regarding
how the model coupling implementations work.
1. Import of Microgrid Data¶
Import microgrid data with a predefined selection list:
for set_number, set in enumerate(microgrid_set_list): # top region microgrid setting
top_region_name = data['site'].index.get_level_values(1)[set_number]
for type_nr, quantity_nr in enumerate(set):
microgrid_entries = microgrid_data_initial[type_nr]['site'].index.get_level_values(1)
n = 0
while n < quantity_nr:
microgrid_data_input = copy.deepcopy(microgrid_data_initial[type_nr])
for entry in microgrid_entries:
Note
So far, demand and RE capacity factor timeseries are scaled for entire microgrid categories of a region. In comparison to the variety of millions of demand and weather curves of large regions, this leads to unrealistically high simultaneity as the number of different timeseries in the model is limited. Thereby, peaks for generation and demand curves get clearly higher leading to overestimated peak load capacitiy requirements and thus increasing overall system costs. The idea of a quantity number >1 in the selection list was to build different microgrids of the same type with automated timeseries variability to counteract this effect. Due to computational limits, this hasn’t been pursued yet but is kept in the script for potential future work. However, in our approach, this increased peaks can be reduced with the applied timeseries aggregation method that has a beneficial smoothing effect on demand curves.
2. Model Connection¶
Specification of the DS data to the overlying regions by defining unique indices for each parameter and region and the automated definition of a direct connection representing the transformer interface between both system levels:
def create_microgrid_data(microgrid_data_input, entry, n, top_region_name):
### Parameter Indexing
microgrid_data_input['site'].rename(
index={entry: entry + str(n + 1) + '_' + top_region_name}, level=1, inplace=True)
microgrid_data_input['commodity'].rename(
index={entry: entry + str(n + 1) + '_' + top_region_name}, level=1, inplace=True)
microgrid_data_input['process'].rename(
index={entry: entry + str(n + 1) + '_' + top_region_name}, level=1, inplace=True)
microgrid_data_input['process_commodity'].rename(
index={entry: entry + str(n + 1) + '_' + top_region_name}, level=1, inplace=True)
microgrid_data_input['demand'].rename(
columns={entry: entry + str(n + 1) + '_' + top_region_name}, level=0, inplace=True)
microgrid_data_input['supim'].rename(
columns={entry: entry + str(n + 1) + '_' + top_region_name}, level=0, inplace=True)
microgrid_data_input['storage'].rename(
index={entry: entry + str(n + 1) + '_' + top_region_name}, level=1, inplace=True)
microgrid_data_input['dsm'].rename(
index={entry: entry + str(n + 1) + '_' + top_region_name}, level=1, inplace=True)
microgrid_data_input['buy_sell_price'].rename(
columns={entry: entry + str(n + 1) + '_' + top_region_name}, level=0, inplace=True)
microgrid_data_input['eff_factor'].rename(
columns={entry: entry + str(n + 1) + '_' + top_region_name}, level=0, inplace=True)
### for transmission data indexes on two levels must be changed
microgrid_data_input['transmission'].rename(
index={entry: entry + str(n + 1) + '_' + top_region_name}, level=1, inplace=True)
microgrid_data_input['transmission'].rename(
index={entry: entry + str(n + 1) + '_' + top_region_name}, level=2, inplace=True)
### Transformer Interface
microgrid_data_input['transmission'].rename(
index={'top_region_dummy': top_region_name}, level=1, inplace=True)
microgrid_data_input['transmission'].rename(
index={'top_region_dummy': top_region_name}, level=2, inplace=True)
return microgrid_data_input
3. Parameter Scaling¶
Scaling of parameters with appropriate multipliers (see How to Determine Multipliers) to represent the multitude of the distribution systems:
def multiplicator_scaling(mode, data, microgrid_data_input, microgrid_multiplicator_list, set_number, type_nr):
### determine multiplicator for region and microgrid type
multi = data['transdist_share'].values[0] * microgrid_multiplicator_list[set_number][type_nr]
### base voltage is scaled with the root value of the multiplicator for a correct consideration within the voltage rule
microgrid_data_input['site'].loc[:, 'base-voltage'] *= math.sqrt(multi)
### scale other relevant quantities
microgrid_data_input['commodity'].loc[:, 'max':'maxperhour'] *= multi
microgrid_data_input['process'].loc[:, ['inst-cap', 'cap-lo', 'cap-up', 'cap-block']] *= multi
microgrid_data_input['transmission'].loc[:, ['inst-cap', 'cap-lo', 'cap-up', 'tra-block']] *= multi
microgrid_data_input['storage'].loc[:, ['inst-cap-c', 'cap-lo-c', 'cap-up-c', 'inst-cap-p', 'cap-lo-p',
'cap-up-p', 'c-block', 'p-block']] *= multi
microgrid_data_input['dsm'].loc[:, 'cap-max-do':'cap-max-up'] *= multi
### if tsam activated postpone demand scaling to reduce number of tsam input timeseries, but still pass demand shift
if mode['tsam'] == True:
demand_shift = microgrid_data_input['demand'] * multi
### otherwise also scale demand data
if mode['tsam'] == False:
microgrid_data_input['demand'] *= multi
demand_shift = microgrid_data_input['demand']
return microgrid_data_input, demand_shift
Note
Postponement of demand scaling if tsam is active
The timeseries aggregation method that is described in Time Series Aggregation with Typeperiods is sensitive to duplicated input timeseries. Therefore, only unique timeseries are handed over as input. All households are defined with the same microgrid templates. If these are scaled before handing them over to the TSA method, duplicate profiles with different scales are not recognized. Therefore, in this case the scaling of the demand is postponed.
4. Scenario Shifting¶
Demand shifting between scenarios for better comparability:
def shift_demand(data, microgrid_data_input, set_number, type_nr, demand_shift, loadprofile_BEV, top_region_name,
mobility_transmission_shift, heat_transmission_shift, transdist_eff):
### subtract private electricity demand at distribution level (increased by tdi efficiency) from transmission level considering line losses
data['demand'].iloc[:, set_number] -= demand_shift.loc[:, pd.IndexSlice[:, 'electricity']].sum(axis=1) / transdist_eff
if data['transdist_share'].values[0] == 1:
### store scaled full mobility and heat demand for 100% active distribution network for subsequent scenarios
mobility_transmission_shift[(top_region_name, type_nr)] = loadprofile_BEV * demand_shift.loc[:, pd.IndexSlice[:, 'mobility']].sum().sum() / transdist_eff
COP_ts = microgrid_data_input['eff_factor'].loc[:, pd.IndexSlice[:, 'heatpump_air']].iloc[:,0].squeeze() #get COP timeseries to transform hourly heat to electricity demand
heat_transmission_shift[(top_region_name, type_nr)] = demand_shift.loc[:, pd.IndexSlice[:, 'heat']].sum(axis=1).divide(COP_ts).fillna(0) / transdist_eff
return data, mobility_transmission_shift, heat_transmission_shift
Note
The subsequent full shifting process is explained in detail in the ‘CoTraDis’ application guide
5. RE Profiles¶
Copy capacity factor timeseries for renewable energy resources from top level region to all microgrids within that region
def copy_SupIm_data(data, microgrid_data_input, top_region_name):
for col in microgrid_data_input['supim'].columns:
microgrid_data_input['supim'].loc[:, col] = data['supim'].loc[:, (top_region_name, col[1])]
return microgrid_data_input
6. Reactive Power Flows¶
Model new imaginary lines to enable reactive power flow on respective lines with defined resistance:
def add_reactive_transmission_lines(microgrid_data_input):
### copy transmission lines with resistance to model transmission lines for reactive power flows
reactive_transmission_lines = microgrid_data_input['transmission'][microgrid_data_input['transmission'].loc[:, 'resistance'] > 0]
reactive_transmission_lines = reactive_transmission_lines.copy(deep = True)
reactive_transmission_lines.rename(index={'electricity': 'electricity-reactive'}, level=4, inplace=True)
### set costs to zero as lines are not really built -
reactive_transmission_lines.loc[:, 'inv-cost':'var-cost'] *= 0
### concat new line data
microgrid_data_input['transmission'] = pd.concat([microgrid_data_input['transmission'], reactive_transmission_lines], sort=True)
return microgrid_data_input
And Implement reactive power outputs as commodity according to predefined power factors for processes:
def add_reactive_output_ratios(microgrid_data_input):
pro_Q = microgrid_data_input['process'][microgrid_data_input['process'].loc[:, 'pf-min'] > 0]
ratios_elec = microgrid_data_input['process_commodity'].loc[pd.IndexSlice[:, :, 'electricity', 'Out'], :]
for process_idx, process in pro_Q.iterrows():
for ratio_P_idx, ratio_P in ratios_elec.iterrows():
if process_idx[2] == ratio_P_idx[1]:
ratio_Q = ratios_elec.loc[pd.IndexSlice[:, ratio_P_idx[1], 'electricity', 'Out'], :].copy(deep = True)
ratio_Q.rename(index={'electricity': 'electricity-reactive'}, level=2, inplace=True)
microgrid_data_input['process_commodity'] = microgrid_data_input['process_commodity'].append(ratio_Q)
microgrid_data_input['process_commodity'] = microgrid_data_input['process_commodity']\
[~microgrid_data_input['process_commodity'].index.duplicated(keep='first')]
return microgrid_data_input
7. Concatenation¶
Concatenation of the previously processed data from both system levels:
def concatenate_with_micros(data, microgrid_data):
data['site'] = pd.concat([data['site'], microgrid_data['site']], sort=True)
data['commodity'] = pd.concat([data['commodity'], microgrid_data['commodity']],sort=True)
data['process'] = pd.concat([data['process'], microgrid_data['process']],sort=True)
data['process_commodity'] = pd.concat([data['process_commodity'], microgrid_data['process_commodity']],sort=True)
data['process_commodity'] = data['process_commodity'][~data['process_commodity'].index.duplicated(keep='first')]
data['demand'] = pd.concat([data['demand'], microgrid_data['demand']], axis=1,sort=True)
data['supim'] = pd.concat([data['supim'], microgrid_data['supim']], axis=1,sort=True)
data['transmission'] = pd.concat([data['transmission'], microgrid_data['transmission']],sort=True)
data['storage'] = pd.concat([data['storage'], microgrid_data['storage']],sort=True)
data['dsm'] = pd.concat([data['dsm'], microgrid_data['dsm']],sort=True)
data['buy_sell_price'] = pd.concat([data['buy_sell_price'], microgrid_data['buy_sell_price']], axis=1,sort=True)
data['eff_factor'] = pd.concat([data['eff_factor'], microgrid_data['eff_factor']], axis=1,sort=True)
return data
8. Worklfow¶
The workflow of all previously described transdisthelper.py implementation is illustrated below: